تشخیص علائم راهنمایی و رانندگی-نانو درجه خودروی خودران Udacity-سری آموزش های عمیق 3

1. مقدمه
شبکه عصبی کانولوشن (CNN) یک ابزار قدرتمند در بینایی رایانه و اتومبیل های خودران است. تشخیص علائم راهنمایی و رانندگی یکی از وظایف اصلی در رانندگی خودکار است زیرا ورودی نشانه ای که در تصویر وجود دارد را به تصمیم گیری می دهد. من این پروژه را به عنوان بخشی از دوره مهندسی خودروهای خودران Udacity انجام داده ام و تمام اعتبار به آنها تعلق می گیرد. اگر مایل به معرفی مختصر CNN هستید ، لطفاً از مقاله قبلی من در این مجموعه دیدن کنید.
2. مجموعه داده
آموزش ، اعتبار سنجی و مجموعه داده های آزمایش در قالب ترشی به ما ارائه شده است. هر مجموعه داده شامل تعدادی تصویر و برچسب آن است. برای بارگیری داده ها از ترشی می توانیم از کد زیر استفاده کنیم.
# بارگیری داده های ترشی شده
ترشی وارداتی
وارد کردن پانداها به صورت pd
وارد کردن numpy به عنوان np
# TODO: این مورد را بر اساس جایی که داده های آموزش و آزمایش را ذخیره کرده اید ، پر کنید
training_file = 'traffic-علائم-داده/train.p'
validation_file = 'traffic-علائم-داده/valid.p'
testing_file = 'traffic-علائم-داده/test.p'
با open (training_file، mode = 'rb') به صورت f:
قطار = pickle.load (f)
با باز (validation_file ، mode = 'rb') به عنوان f:
معتبر = pickle.load (f)
با باز کردن (testing_file ، mode = 'rb') به صورت f:
test = pickle.load (f)
X_train، y_train = قطار ['ویژگی ها'] ، قطار ['برچسب ها]]
X_valid، y_valid = معتبر ['ویژگی ها'] ، معتبر ['برچسب ها]]
X_test، y_test = test ['features'] ، test ['labels'] داده های ترشی شده یک فرهنگ لغت با 4 جفت کلید/مقدار است:
'ویژگی ها' 4 بعدی است آرایه ای حاوی داده های پیکسل خام از تصاویر علائم راهنمایی و رانندگی ، (مثالهای عددی ، عرض ، ارتفاع ، کانالها). 'labels' یک آرایه 1 بعدی است که حاوی برچسب/شناسه کلاس ترافیک است. فایل signnames.csv شامل id -> نگاشت های نام برای هر شناسه است. "اندازه" لیستی است که شامل چندتایی (عرض ، ارتفاع) نشان دهنده عرض و ارتفاع اصلی تصویر است. < uli> 'coords' لیستی شامل چندتایی ، (x1 ، y1 ، x2 ، y2) است که مختصات یک کادر محدود کننده در اطراف علامت در تصویر را نشان می دهد. این مختصات تصویر اصلی را فرض می کنند. داده های منتخب شامل نسخه های تجدید شده (32 در 32) از این تصاویر است.
در اینجا آمار خلاصه ای از مجموعه داده های علائم راهنمایی و رانندگی است:
تعداد نمونه های آموزشی = 34799
تعداد نمونه های اعتبارسنجی = 4410
تعداد نمونه های آزمایش = 12630
شکل داده تصویر = (32 ، 32 ، 3)
تعداد کلاسها = 43

مجموعه داده نمونه
3. پیش پردازش
قبل از شروع فرآیندهای آموزشی ، مجموعه داده ها باید دارای پیش پردازش اولیه با استفاده از نرمال سازی ، مقیاس خاکستری و غیره باشند. من متوجه شدم که عادی سازی به خودی خود نتیجه خروجی بسیار خوبی را ارائه می دهد و از سایر تکنیک های پیش پردازش استفاده نمی کند.
من تغییراتی در داده ها انجام دادم تا بتواند ماهیت تصادفی مجموعه داده را افزایش دهد.
از sklearn.utils وارد کردن shuffle
X_train، y_train = shuffle (X_train ، y_train)
X_valid، y_valid = shuffle (X_valid، y_valid)
X_test، y_test = shuffle (X_test، y_test)
سپس نرمال سازی را انجام دهید تا مطمئن شوید داده های تصویر نرمال شده اند به طوری که داده ها دارای واریانس صفر و مساوی هستند.
#نامگذاری
X_train = (X_train-X_train.mean ())/(np.max (X_train) -np.min (X_train))
X_valid = (X_valid-X_valid.mean ())/(np.max (X_valid) -np.min (X_valid))
X_test = (X_test-X_test.mean ())/(np.max (X_test) -np.min (X_test))
تصویر قبل و بعد از عادی سازی در اینجا نمایش داده می شود.
قبل:

بعد از:
< img src = "https://cdn-images-1.medium.com/max/426/0*5bMR7JQjVTQ7HCEf.png">
4. معماری مدل
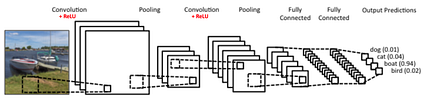
تصویر فوق مربوط به معماری LeNet-5 که به عنوان یکی از اولین شبکه های عصبی کانولوشن (CNN) در نظر گرفته می شود. ما از LeNet-5 برای پروژه تشخیص علائم راهنمایی و رانندگی استفاده می کنیم.
شبه کد معماری به شرح زیر است:
ورودی > bb> معماری LeNet 32x32x3 را می پذیرد تصویر به عنوان ورودی معماری لایه 1: تحولی. شکل خروجی باید 28x28x6 باشد. فعال سازی. انتخاب شما ازتابع فعال سازی. تجمع. شکل خروجی باید 14x14x6 باشد. لایه 2: متحرک. شکل خروجی باید 10x10x16 باشد. فعال سازی. انتخاب عملکرد فعال سازی شما. جمع آوری. شکل خروجی باید 5x5x16 باشد. صاف شود. شکل خروجی لایه نهایی را به گونه ای صاف کنید که به جای سه بعدی یک بعدی باشد. ساده ترین راه این است که از tf.contrib.layers.flatten استفاده کنید که قبلاً برای شما وارد شده است. لایه 3: کاملاً متصل است. این باید 120 خروجی داشته باشد. فعال سازی. انتخاب عملکرد انتخابی شما. لایه 4: کاملاً متصل شده است. این باید 84 خروجی داشته باشد. فعال سازی. انتخاب عملکرد فعال سازی شما. لایه 5: کاملاً متصل (Logits). این باید 43 خروجی داشته باشد. اجرای کد واقعی در زیر آمده است:
def LeNet (x):
# لایه 1: تحولی. ورودی = 32x32x3. خروجی = 28x28x6.
conv1_W = tf. متغیر (tf.truncated_normal (شکل = (5 ، 5 ، 3 ، 6) ، میانگین = 0 ، stddev = 0.1))
conv1_b = tf. متغیر (tf.zeros (6))
conv1 = tf.nn.conv2d (x ، conv1_W ، گامها = [1 ، 1 ، 1 ، 1] ، padding = 'VALID') + conv1_b
# فعال سازی 1.
conv1 = tf.nn.relu (conv1) # جمع آوری. ورودی = 28x28x6. خروجی = 14x14x6.
conv1 = tf.nn.max_pool (conv1 ، ksize = [1 ، 2 ، 2 ، 1] ، گام ها = [1 ، 2 ، 2 ، 1] ، padding = 'VALID')
# لایه 2: تحولی. ورودی = 14x14x6. خروجی = 10x10x16.
conv2_W = tf. متغیر (tf.truncated_normal (شکل = (5 ، 5 ، 6 ، 16) ، میانگین = 0 ، stddev = 0.1))
conv2_b = tf. متغیر (tf.zeros (16))
conv2 = tf.nn.conv2d (conv1، conv2_W، strides = [1، 1، 1، 1]، padding = 'VALID') + conv2_b
# فعال سازی 2.
conv2 = tf.nn.relu (conv2) # جمع آوری. ورودی = 10x10x16. خروجی = 5x5x16.
conv2 = tf.nn.max_pool (conv2 ، ksize = [1 ، 2 ، 2 ، 1] ، گام ها = [1 ، 2 ، 2 ، 1] ، padding = 'VALID')
# صاف کنید. ورودی = 5x5x16. خروجی = 400
مسطح = مسطح (conv2)
#ضرب ماتریس
#ورودی: 1x400
#وزن: 400x120
#ضرب ماتریس (قاعده محصول نقطه)
#خروجی = 1x400 * 400 * 120 => 1x120
# لایه 3: کاملاً متصل است. ورودی = 400. خروجی = 120.
fullc1_W = tf. متغیر (tf.truncated_normal (شکل = (400 ، 120) ، میانگین = 0 ، stddev = 0.1))
fullc1_b = tf. متغیر (tf.zeros (120))
fullc1 = tf.matmul (مسطح ، کاملاc1_W) + fullc1_b
# فعال سازی لایه کامل متصل 1.
fullc1 = tf.nn.relu (کامل c1)
# لایه 4: کاملاً متصل است. ورودی = 120. خروجی = 84.
fullc2_W = tf. متغیر (tf.truncated_normal (شکل = (120 ، 84) ، میانگین = 0 ، stddev = 0.1))
fullc2_b = tf. متغیر (tf.zeros (84))
fullc2 = tf.matmul (fullc1 ، fullc2_W) + fullc2_b
# فعال سازی لایه کامل متصل 2.
fullc2 = tf.nn.relu (کامل c2)# لایه 5: کاملاً متصل شده است. ورودی = 84. خروجی = 43.
fullc3_W = tf. متغیر (tf.truncated_normal (شکل = (84 ، 43) ، میانگین = 0 ، stddev = 0.1))
fullc3_b = tf. متغیر (tf.zeros (43))
logits = tf.matmul (fullc2 ، fullc3_W) + fullc3_b
بازگشت logits 5. آموزش و ارزیابی
برای آموزش مدل ، بعد از چندین روش آزمایش و خطا از پارامتر زیر استفاده کردم.
learning_rate = 0.001
epochs = 40
batch_size = 64
مدل Lenet logits و آنتروپی متقاطع را ارائه می دهد. سپس عملیات از دست دادن خطا را در مقایسه با نتیجه واقعی و نتیجه پیش بینی شده می دهد. در نهایت از بهینه ساز Adam برای بهینه سازی استفاده می شود.
logits = LeNet (x)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits (برچسب ها = one_hot_y ، logits = logits)
loss_operation = tf.reduce_mean (cross_entropy)
optimizer = tf.train.AdamOptimizer (نرخ_آموزش = میزان_آموزش)
training_operation = optimizer.minimize (loss_operation)
مراحل فوق حرکت رو به جلو و عقب را انجام می دهد و انجام این کار به صورت تکراری خطا را در پایان کاهش می دهد.
با tf.Session ( ) به عنوان sess:
sess.run (tf.global_variables_initializer ())
num_examples = len (X_train)
چاپ ("آموزش ...")
چاپ()
برای i در محدوده (دوره ها):
X_train ، y_train = shuffle (X_train ، y_train)
برای افست در محدوده (0 ، num_examples ، batch_size):
end = offset + batch_size
batch_x ، batch_y = X_train [offset: end] ، y_train [offset: end]
sess.run (Training_operation، feed_dict = {x: batch_x، y: batch_y})
valid_loss ، valid_accuracy = ارزیابی (X_valid ، y_valid)
print ("Epoch {}، Validation loss = {: .3f}، Validation Accuracy = {: .3f}". format (i+1، valid_loss، valid_accuracy))
چاپ()
saver1.save (sess، './classifier')
print ("مدل ذخیره شد") کد بالا روش معمول اجرای آموزش در Tensorflow است. سپس عملکرد اضافه شده در زیر را برای بررسی صحت اعتبارسنجی در هر دوره فراخوانی کنید.
برای ارزیابی (X_data ، y_data):
num_examples = len (X_data)
مجموع_دقت = 0
مجموع ضرر = 0
sess = tf.get_default_session ()
برای افست در محدوده (0 ، num_examples ، batch_size):
batch_x، batch_y = X_data [offset: offset+batch_size]، y_data [offset: offset+batch_size]
ضرر ، دقت = sess.run ([ضرر_عمل ، دقت_عمل] ، feed_dict = {x: batch_x ، y: batch_y})
total_accuracy += (دقت * لن (batch_x))
total_loss += (ضرر * لن (batch_x))
total_loss/num_examples ، total_accuracy/num_examples 7 را بازگردانید. آزمایش
پس از اتمام آموزش ، می توانیم مدل را در مقابل مجموعه داده های آزمایش اجرا کنیم تا صحت نهایی را بررسی کنیم. در این مورد ، مدل آموزش دیده قادر است 6 مورد از 6 علائم راهنمایی و رانندگی را به درستی حدس بزند که دقت آن را 100٪ می دهد.
نتیجه پیش بینی به شرح زیر است:

جدول فوق نشان می دهد که اگر تصویری از علائم راهنمایی و رانندگی ارائه دهیم ، می تواند پیش بینی کندآن را به طور دقیق به دلیل محدودیت فضای مقاله ، من فقط برچسب روی ستون های تصویر را به جای تصویر ارائه کرده ام. p> اگر از نوشتن من خوشتان آمد ، من را در Github ، Linkedin و/یا نمایه متوسط دنبال کنید.
سری آموزش های عمیق
سری یادگیری عمیق 1- معرفی به یادگیری عمیق سری یادگیری عمیق 2-طبقه بندی تصویر ساده با استفاده از یادگیری عمیق مرجع
مهندس اتومبیل خودران Udacity نانو درجه علم این که چگونه ماشین به نظر می رسد مغز ما را فریب می دهد
[ بازدید : 5 ] [ امتیاز : 0 ] [ نظر شما :
]


 < h1> نه فقط قطعات با مقاومت کم
< h1> نه فقط قطعات با مقاومت کم 
 AdobeStock_219400471.jpeg (Dragana Gordic)
AdobeStock_219400471.jpeg (Dragana Gordic)  ترفندهای زیادی پیش می آید دستکاری صداهای ماشین فراتر از فیلم هایی مانند "Mad Max: Fury Road". اعتبار: برادران وارنر
ترفندهای زیادی پیش می آید دستکاری صداهای ماشین فراتر از فیلم هایی مانند "Mad Max: Fury Road". اعتبار: برادران وارنر  عکس توسط Joshua J. Cotten در Unsplash
عکس توسط Joshua J. Cotten در Unsplash 

 برد رافنسپرگر ، وزیر امور خارجه گرجستان ، در یک کنفرانس خبری روز چهارشنبه ، 11 نوامبر 2020 ، در آتلانتا صحبت می کند. مقامات انتخابات گرجستان اعلام کرده اند که نتایج انتخابات ریاست جمهوری را بازرسی می کند که باعث بازشماری کامل دست می شود. اعتبار عکس: Brynn Anderson/AP
برد رافنسپرگر ، وزیر امور خارجه گرجستان ، در یک کنفرانس خبری روز چهارشنبه ، 11 نوامبر 2020 ، در آتلانتا صحبت می کند. مقامات انتخابات گرجستان اعلام کرده اند که نتایج انتخابات ریاست جمهوری را بازرسی می کند که باعث بازشماری کامل دست می شود. اعتبار عکس: Brynn Anderson/AP